In today’s data-driven world, machine learning powers everything from recommendation engines to fraud detection systems. But how do we truly know if these models work effectively in the real world?
The answer lies in performance metrics in machine learning.
These quantitative measures are the backbone of model validation, helping you evaluate, compare, and optimize models to ensure their predictions are both accurate and reliable. Choosing the right metric can be the difference between a model that just looks good on paper and one that drives real business value.
Heres a video about confusion matric with solved example
What Are Machine Learning Performance Metrics?
Performance metrics are quantitative measures used to assess how well a model performs on a given dataset. They bridge the gap between abstract prediction and concrete decision-making by measuring:
- Accuracy — How often the model is correct
- Efficiency — Computational cost and speed
- Robustness — Performance across different conditions
- Generalization — Ability to handle unseen data
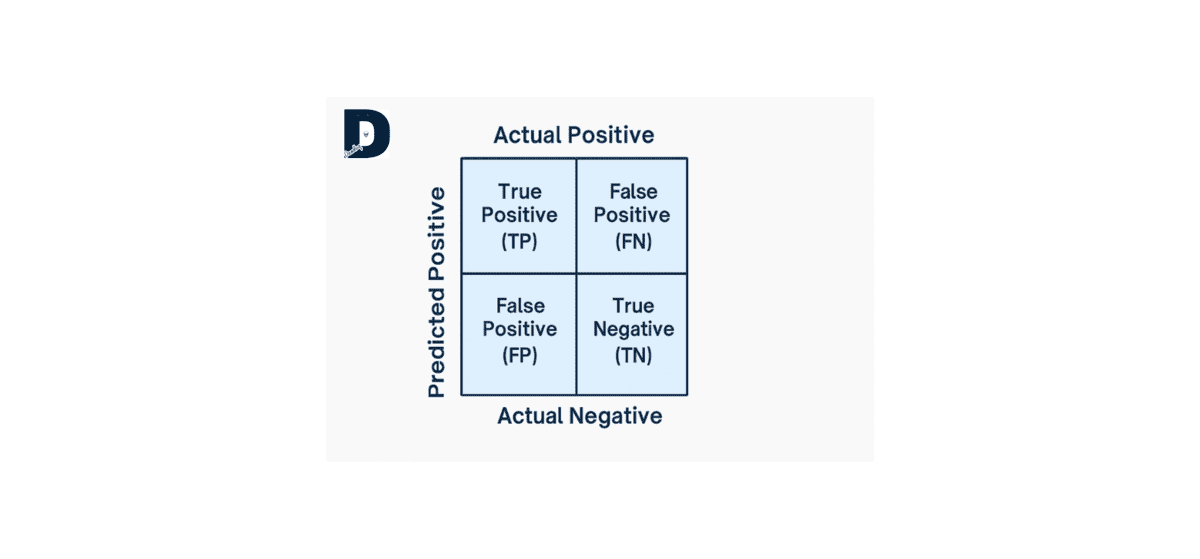
Understanding the Confusion Matrix
Before diving into metrics, it’s crucial to understand the confusion matrix components:
| Term | Definition |
|---|---|
| True Positive (TP) | Correctly predicted positive cases |
| True Negative (TN) | Correctly predicted negative cases |
| False Positive (FP) | Incorrectly predicted as positive (Type I error) |
| False Negative (FN) | Incorrectly predicted as negative (Type II error) |
All classification metrics derive from these four values. Learn more about confusion matrices from scikit-learn documentation.
1. Classification Metrics: Evaluating Categorical Models
Classification models predict categorical outcomes (e.g., spam vs. not spam, fraud vs. no fraud). Because datasets are often imbalanced, relying on simple Accuracy is a common pitfall.
| Metric | Formula | Description | When to Use |
|---|---|---|---|
| Accuracy | (TP + TN) / (TP + TN + FP + FN) | Overall correctness of the model | Balanced datasets where all classes matter equally |
| Precision | TP / (TP + FP) | How many predicted positives were actually correct | When false positives are costly (e.g., spam filters) |
| Recall (Sensitivity) | TP / (TP + FN) | How many actual positives were correctly identified | When false negatives are costly (e.g., disease detection) |
| F1 Score | 2 × (Precision × Recall) / (Precision + Recall) | Harmonic mean balancing precision and recall | Imbalanced datasets needing balance |
| Specificity | TN / (TN + FP) | How many actual negatives were correctly identified | When correctly identifying negatives matters |
| AUC-ROC | Area under ROC curve | Model’s ability to distinguish between classes | Threshold-independent evaluation |
| MCC | (TP×TN – FP×FN) / √[(TP+FP)(TP+FN)(TN+FP)(TN+FN)] | Balanced measure using all confusion matrix values | Highly imbalanced datasets |
Key Insight: When data is imbalanced, rely on Precision, Recall, F1-Score, or MCC—not Accuracy alone.
Read more about ROC curves and AUC from Google’s ML Crash Course.
Multi-Class Averaging: Macro vs. Micro
When dealing with more than two classes, you must aggregate the per-class metrics:
| Averaging Type | Description | When to Use |
|---|---|---|
| Macro-Average | Calculate metric for each class, then average | When all classes are equally important |
| Micro-Average | Aggregate all TPs, FPs, FNs across classes, then calculate | When you care about overall performance weighted by class size |
| Weighted-Average | Average metrics weighted by class support | When accounting for class imbalance |
Learn more about multi-class metrics from scikit-learn.
2. Regression Metrics: Evaluating Continuous Models
Regression models predict continuous values (e.g., prices, temperatures, stock values). These performance metrics in machine learning focus on the magnitude and nature of prediction errors.
MAE vs. RMSE: The Core Distinction
| Metric | Formula | Emphasis | When to Use |
|---|---|---|---|
| Mean Absolute Error (MAE) | (1/n) × Σ|yi – ŷi| | Treats all errors equally | When all errors matter equally; robust to outliers |
| Root Mean Squared Error (RMSE) | √[(1/n) × Σ(yi – ŷi)²] | Penalizes larger errors more heavily | When large errors are especially problematic |
Decision Guide:
- Use MAE when: All errors should be weighted equally, you have outliers, you want easier interpretability
- Use RMSE when: Large errors are especially problematic, you’re using gradient-based optimization, comparing with existing literature
Other Key Regression Metrics
| Metric | Formula | Description | When to Use |
|---|---|---|---|
| Mean Squared Error (MSE) | (1/n) × Σ(yi – ŷi)² | Average squared difference | Optimization (differentiable), penalizing large errors |
| R² (Coefficient of Determination) | 1 – (SS_residual / SS_total) | Proportion of variance explained (range: -∞ to 1) | Understanding model’s explanatory power |
| Adjusted R² | 1 – [(1-R²)(n-1) / (n-p-1)] | R² adjusted for number of predictors | Comparing models with different feature counts |
| MAPE | (100/n) × Σ|(yi – ŷi) / yi| | Average percentage error | Scale-independent comparison across datasets |
Pro tip: Use R² for interpretability, RMSE for model comparison, and MAE for robustness to outliers.
Learn more about regression metrics from scikit-learn.
3. Clustering Metrics: Validating Unsupervised Grouping
Clustering algorithms group similar data points. Since these are unsupervised, metrics evaluate grouping quality based on internal structure or comparison to known labels.
| Metric | Range | Description | When to Use |
|---|---|---|---|
| Silhouette Score | -1 to 1 (higher is better) | Measures cohesion within clusters and separation between | Validating cluster quality without ground truth |
| Davies-Bouldin Index | 0 to ∞ (lower is better) | Ratio of within-cluster to between-cluster distances | Comparing different clustering algorithms |
| Calinski-Harabasz Index | 0 to ∞ (higher is better) | Ratio of between-cluster to within-cluster variance | Fast computation for large datasets |
| Adjusted Rand Index (ARI) | -1 to 1 (1 = perfect) | Similarity between predicted and true clusters | When you have ground truth labels |
Read more about clustering evaluation from scikit-learn.
4. Ranking & Recommendation Metrics
These performance metrics in machine learning evaluate the quality of ordered lists, such as search results or product recommendations.
| Metric | Description | When to Use |
|---|---|---|
| Precision / Recall | Precision/recall for only the top K results | When users only view a limited list |
| Mean Average Precision (MAP) | Average of precision values at each relevant item position | When ranking order is critical |
| NDCG | Ranking quality with position-based weighting | When items have graded relevance (not binary) |
| Hit Rate | Percentage of times relevant item appears in top K | Simple binary evaluation of success |
Why Your Metric Choice is a Business Decision
Choosing the wrong metric can be disastrous. The evaluation must always align with the real-world cost of errors.
| Scenario | Wrong Metric | Why It Fails | Right Metric |
|---|---|---|---|
| Fraud Detection (1% fraud rate) | 99% Accuracy | Model predicting “no fraud” always achieves 99% accuracy but catches zero fraud | Precision, Recall, F1-Score |
| Medical Diagnosis | Accuracy only | Doesn’t reveal cost: False Negative (missed disease) is far costlier | Recall (minimize False Negatives) |
| House Price Prediction | MAE only | Doesn’t emphasize that $100K error on luxury homes is more problematic | RMSE (penalizes large errors) |
Cost-Benefit Alignment
Always align performance metrics in machine learning with:
- Business goals (e.g., minimizing false negatives in healthcare)
- Data type and distribution
- Cost of different error types
Best Practices for Robust Model Evaluation
| Practice | Why It Matters | How to Implement |
|---|---|---|
| Use Cross-Validation | Single train-test split can be misleading | K-fold CV (typically 5 or 10 folds) |
| Analyze Confusion Matrices | Reveals where model succeeds and fails | Examine full matrix, not just summary metrics |
| Report Multiple Metrics | No single metric tells complete story | Report Accuracy + Precision + Recall + F1 + AUC-ROC |
| Consider Business Costs | Real-world costs aren’t equal | Create custom cost-weighted metrics |
| Test on Held-Out Data | Ensures true generalization | Reserve data never used in training/tuning |
| Monitor Over Time | Models degrade as distributions shift | Continuously track production metrics |
Learn more about cross-validation from scikit-learn.
Key Takeaways
The best performance metrics in machine learning are those that answer your specific business question and align with real-world costs.
| Category | Primary Goal | Key Metrics |
|---|---|---|
| Classification | Handle imbalance, cost of errors | Precision, Recall, F1-Score, AUC-ROC, MCC |
| Regression | Penalize large errors, interpretability | MAE, RMSE, R², Adjusted R² |
| Clustering | Measure cohesion/separation | Silhouette Score, ARI, Davies-Bouldin Index |
| Ranking | Evaluate ordered results | Precision, MAP, NDCG |
Conclusion
Performance metrics in machine learning are the heartbeat of model validation. They transform raw predictions into meaningful insights, guiding you toward better, more trustworthy models.
The key is not just knowing the formulas, but understanding:
- When each metric is appropriate
- Why certain metrics fail in specific contexts
- How to align metrics with real-world business objectives
By mastering these metrics, you gain the confidence to not only improve your model’s performance but also trust your data-driven decisions.
Want more cool ML breakdowns like this? Stick around and follow Deadloq — we make data science simple and practical.